
Unloaded Sheets
—
If after you pass multiple files to vd on the command-line, you go straight to the Sheets Sheet, you'll see that only the first one is loaded:
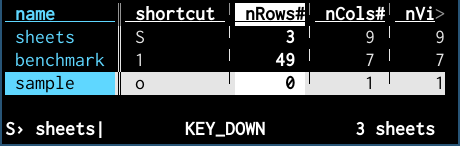
When a sheet is first created, it is considered "unloaded" (literally sheet.rows is UNLOADED).
It can stay in this dormant state indefinitely, and is quite lightweight.
Then, as it's about to be drawn for the first time, the sheet starts its loading process (via sheet.reload()), to read the data into memory.
These reloads are spawned in a separate thread; this is what makes VisiData responsive as a sheet is loading.
But there is a problem here. If too many large sheets are loading at once, your laptop supercomputer would still slow to a crawl.
So if you have 100GB of .csv files in a directory and you do vd *.csv (which is a reasonable thing to want to do, especially if you have 100GB of .csv), VisiData only starts loading the top sheet (the first one given on the command-line) in order to draw it. The other sheets remain unloaded, as you can see on the SheetsSheet. When you jump to one of the unloaded sheets, it will start loading.
Now, if you have a bunch of small sheets and go to the Sheets Sheet expecting to compare or join them straight away, you might be disappointed to find them unloaded and unusable.
Fear not! To load multiple sheets at the same time, go to the Sheets Sheet, select the sheets you want to load, and then reload-selected with g Ctrl+R.

Now you can go forth and jump around bundles of csvs to your heart's delight, secure in the knowledge that VisiData will only read into memory what you intentionally want to engage with.
[written by Saul Pwanson 2020-02-10]
[edited by Anja Kefala 2020-02-11]